
The Holy Grail

Wouldn’t it be wonderful if there was a single blood test that could pick up not just one, but dozens of early cancers, allowing early treatment, and countless lives to be saved? According to an auspiciously named American high tech company, GRAIL, Inc., just such a goal might be in reach. It claims it’s Galleri blood test, which uses clever technology to detect fragments of tumour DNA in the blood, can detect many common cancers in the early stages, with a false positive rate below 1%. On the back of this, it has secured a ‘commercial partnership program‘ with the NHS to pilot the test in around 165,000 people, starting next year. Hatt Mancock, the health secretary who increasingly resembles a schoolboy who has just shot his neighbour’s dog with a poison dart, can hardly contain his excitement. ‘We are building a world-leading diagnostics industry in the UK — not just for coronavirus, but for other diseases too,’ he gushed. Could this be the ‘exciting and ground-breaking new blood test’ Mancock says it is, or is it another world-beating Operation Bonfire of taxpayers’ money?
Most of the people enrolled in the pilot will be aged 50 and over, and asymptomatic, so this is mass screening. To the simple mind, screening is intuitively attractive. It stands to reason that picking up early cancers and treating them must be a good thing, just as picking up asymptomatic covid cases early, and isolating them, must be a good thing. But, as covid has taught us, screening is never simple. Not only do we have to concern ourselves with the accuracy of the test, its sensitivity and specificity, but we also have to consider how common the condition is in the real world, as this has a major effect on the false positive rate. We have also learnt that what happens after a positive test is important: if the ‘treatment’, self-isolation, doesn’t work, because too few people do self-isolate, then the test becomes pointless. The same principle applies to all screening: if the treatment doesn’t work, or doesn’t even exist, then screening will have no benefits, leaving only potential harms.
Another major problem is bias in studies of screening that make it appear that screening works — of course it works, stands to reason it works — when it doesn’t. A classic example is lead time bias. Imagine two people, both asymptomatic, but both harbouring an early untreatable cancer that will kill them both in two years time. Next week, one has a screening test for the cancer, the other doesn’t, and the screened one tests positive, and ends up with a cancer diagnosis, while the other carries on normally, blissfully unaware of the ticking time bomb within. A year later, the unscreened person develops symptoms, and gets a cancer diagnosis, and another year later, both die. Mr Stands-to-Reason hears about both patients — maybe they were friends of his — and says, look, screening obviously works, my screened friend survived twice as long as my unscreened friend. It does indeed look that way, but as you will have spotted, that is not at all what happened. Both survived the same length of time, only the screened person had the burden of knowing of the cancer, and very likely enduring treatment, for twice as long. All in all, no benefit, just the harm of being ill with cancer for twice as long.
That is perhaps an extreme example, but it serves to remind us that we should be wary of claims that screening works. Another major problem is poorly performing screening tests, with low threshold PSA screening for prostate cancer the classic example: it picks up far too many men who would never have died from their prostate cancer. The key thing here — and we are well placed to consider this, given the recent fandango over covid testing — is the test’s specificity, that is, how good, or specific, it is at only being positive when the condition it tests for is actually present. A highly specific test implies a low false positive rate — but there is a catch. If the prevalence of the condition of interest is low, then even a highly specific test can lead to a significant number of false positives. This happens because even a low rate applied to a large number, all those people who don’t have the disease because the prevalence is low, inevitably produces a large number of false positives.
Manufacturers of screening tests know this only too well, and so they tend to cook the books when running tests on their screening tests, by setting up trials in which the prevalence is artificially high. Information on the holy GRAIL test is sparse — never a good sign — but what there is suggests that this is indeed exactly what GRAIL have done. In a paper published in June this year, the company reports the results of a study of the sensitivity and specificity of its multi-cancer detection test. The headline figures are that the test has an overall specificity of 99.3% for any cancer (on the face of it, good), and a sensitivity for early (stage 1) cancers of 18% (not so good). Sensitivity improves if only selected cancers are included, as it does for later stage disease, but given that later stage disease will almost always mean the cancer is clinically apparent, a screening test becomes irrelevant.
Now let us look at the numbers a bit more closely. They are presented rather opaquely so we will have to reverse engineer them to get a conventional two by two screening test disease positive/negative by test positive/negative table. In the validation arm of the trial, there were 654 people with cancer, and 610 without, with sensitivity and specificity as above, 18% and 99.3% respectively. This, using Dr No’s favourite online diagnostic/screening test calculator, gives us the following two by two table:

Table 1: conventional two by two tabulation to test results, based on figures reported in the GRAIL paper
The sensitivity is none too good, but the specificity, and so false positives — there are only 4 out of a total of 122 positive results — look promising. But there is a big red flag waving over that table: the prevalence of cancer in the study population. At 52%, it is wildly higher than any realistic real world number. What happens if we lower the prevalence to a more realistic number?
Quite what a realistic number is involves a bit of educated guess work, given that we are trying to estimate a number we don’t know, the number of people who we don’t know have cancer. As a rough guide, let’s take the UK annual incidence of all cancers, 367,000, and say that — your guess is as good as Dr No’s — these cancers existed in screen detectable form for two years before diagnosis, meaning that the prevalence of screen detectable cancer at any one time is around 734,000, made up of 376,000 in their first screen detectable year, and 376,000 in their second screen detectable year. Given a UK population of 67 million, that gives us a prevalence of screen detectable cancer of of around 1%. Seems reasonable enough, so lets put that much lower but more realistic prevalence figure into our table, while leaving the sensitivity an specificity as before:
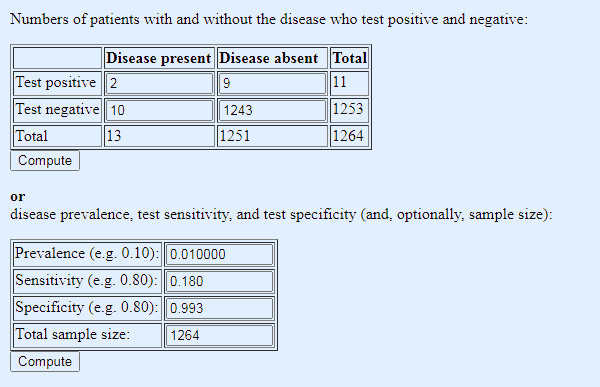
Table 2: same test, same sensitivity and specificity, but prevalence adjusted to a more realistic real world figure (note: 1% gets entered as 0.01)
Oh dear, not so good. Not only do we miss a lot of cancers, because of the low sensitivity, but now the low prevalence has spooked the test positives: of the eleven positives, a full nine are false positives. Nine out of every eleven who test positive will suffer the anxiety of a provisional cancer diagnosis, and while we might hope subsequent diagnostic testing will in turn rule out cancer, they will nonetheless have to endure the unpleasantness of the further tests, and inevitably — because those tests too will have false positives — some will have to endure treatment for a cancer they do not have (or do have, but it was never going to harm them).
Yet the government is once again steaming ahead, rolling out a ‘pilot [of a] potentially revolutionary blood test’ — and note pilot implies a test of feasibility, not a test of the test itself — across the country, even when the scant science there is shows the test at the very least needs further clinical evaluation, in a more realistic real world population. One hopes those invited to participate will give full informed consent, but one fears perhaps they may not. No need to bother with that sort of nonsense, when you are busy chasing a Holy Grail of ‘building a world-leading diagnostics industry in the UK — not just for coronavirus, but for other diseases too’.
Very apt description Dr No…
“[Mancock] who increasingly resembles a schoolboy who has just shot his neighbour’s dog with a poison dart”
Excellent piece, but it just gets worse & worse, doesn’t it.
You know this stuff & probably a signficant proportion of your readership knows it, too. However, our government (and, indeed, their hopeless opposition), appear to be totally ignorant of it. Their grasp of any real science or mathematics seems non-existent. I doubt that they would recognise even a quadratic equation if it bit them on the arse. They don’t know what questions to put to their advisers & very clearly have no idea about weighing up – or interrogating – the answers. Sir Humphrey (or Patrick or Chris or . . . ) is able to manipulate them with impunity.
I read that the Devon & Cornwall police have allocated 10 squad cars to ‘covid patrol’ duties. Has the police entrance exam been updated to include some elementary science? Promotion to Sturmbannführer should depend upon a good score.
Not only 9 false positives, but 10 missed cancers out of the 12 or 13 present! So not much use for screening at all.
Who amongst our noble politicians has vested interests in this?
I’m asking myself if I would want such a test, and I’m thinking I wouldn’t. One of the ‘lay person’ thoughts that I entertain now and then is that doctors generally only see ill people. They don’t necessarily know how apparently well people are functioning. If we all have cancer cells floating around in our systems this doesn’t mean they will overtake us, does it. But spotting them with tests could open the door to much medicalising of conditions that might or might not develop. Or is this too simplistic.
Dr No had better own up to being perhaps slightly disingenuous, or perhaps not. The paper in effect does three analyses (another red flag, though probably sort of OK on this occasion): all (>50) cancers, 12 ‘high-signal’ cancers and individual cancers, and the 18% sensitivity is for all (>50) stage 1 cancers; for the 12 ‘high signal’ stage 1 cancers (an odd-ball list only set down in the Supplementary Information: anus, bladder, colon/rectum, oesophagus, head and neck, liver/bile-duct, lung, lymphoma, ovary, pancreas, plasma cell neoplasm, stomach) it is 39%, but that still means it misses six out of ten early cancers. For individual cancers, the results for stage 1 disease vary widely, perhaps because numbers were small: near zero sensitivity for breast prostate and uterus, better (50-75%) for colon/rectum, bowel oesophagus and pancreas (see Figure 5 in the paper, nut note the small numbers). But as the test is being touted by Hancock as good-to-go for >50 cancers, then perhaps 18% sensitivity is the right one to use.
Tish – “Or is this too simplistic” – not at all, it is at the heart of the debate about screening. Well people are in some important ways very different to symptomatic and ill people. For a start, they are not patients seeking the help of a doctor, they are individuals getting on with their lives, and so the thresholds for intervention, including screening, need to be correspondingly high. And yet screening is one of the areas with an appalling track record for medicalisation and over-treatment, cholesterol screening leading to statination, PSA screening leading to over-diagnosis and treatment of prostate cancer, ditto for breast cancer, and the list goes on.
“If we all have cancer cells floating around in our systems this doesn’t mean they will overtake us, does it.” The answer of course is no, and this also touches on another very interesting question: instead of asking why do some people get cancer, how about asking, given cancers arise spontaneously all the time, why don’t we all get cancer?
Thank you very much, Dr. No, for this response and also that final question: ‘why don’t we all get cancer?’ It is a very crucial question, isn’t it. Also just pondering that even simple ‘screening’ such as having blood pressure done at the surgery can lead to horrendous nonsense and all sorts of inappropriate interventions, if like my other half, you suffer from ‘white coat’ syndrome and happen to be in age group where it’s assumed everything’s falling apart and you need immediate in-put of statins. Also it’s a problem if your GP surgery doctors don’t know you from Adam because you don’t go often, so they have little or no immediate context for diagnosis.
around 734,000, made up of 376,000 in their first screen detectable year, and 376,000 in their second screen detectable year.
It’s as well you said “around”.
Yikes, Dr. No! Have you seen the Pfizer vax is being rolled out any time soon, and have seen the Drs Wodarg and Yeadon petition to the European Medicines Agency?
Article here with link to petition:
https://2020news.de/en/dr-wodarg-and-dr-yeadon-request-a-stop-of-all-corona-vaccination-studies-and-call-for-co-signing-the-petition/
Also of note the Public Health England October publication, quote on page 6:
“RT-PCR detects presence of viral genetic material in a sample but is not able to distinguish whether infectious virus is present.”
Tish – yes indeed, the MSM have been full of nothing else apart from Debenhams going under. One of the interesting questions is why is the UK the first country to approve the vaccine? (Not how, we know that, rapid processing, without, they say corners being cut). My guess it is the same mentality as the clap for carers neighbourhood warden who then goes off to Tesco’s and elbows NHS staff out of the way – a desire to be at the head of the queue when something is in short supply, as the Pfizer vaccine surely is. More generally, there is the problem of any new medicine being, by definition, an unknown. When in clinical practice Dr No tended to avoid ‘the latest drug’ for precisely that reason. It’s only when a drug (or vaccine) has been given to enough people representing all sorts of different risk profiles that you actually get to know what the (serious) rare side effects are. There are plenty of historical examples, some more ‘comic’ than others eg the SSRI sexual side effects missed because the early trials were done on fit virile males with libido to spare, and then of course there are the truly awful ones like thalidomide.
There is one particular side effect which we need to be aware of with covid, antibody-dependent enhancement (ADE) (also sometimes known as antibody enhanced disease, or AED), where an immune system primed by a vaccine goes into overdrive when it meets the real McCoy, and results in enhanced respiratory disease (ERD). (Yes, too many TLAs (three letter abbreviations)!). From the conclusion of a September 2020 Nature Microbiology paper:
“ADE has been observed in SARS, MERS and other human respiratory virus infections including RSV and measles, which suggests a real risk of ADE for SARS-CoV-2 vaccines and antibody-based interventions.”
Just for the record, Dr No is not an anti-vaxxer, just a prudent, and in the case of new drugs and vaccines, a cautious prescriber.